2017年3月25日(周六)下午,由北京大学《儒藏》编纂与研究中心主办、学衡微信公众号协办的“儒藏学衡讲座”第三讲在北京大学理教213教室举行。本次讲座的主讲人为北京大学《儒藏》编纂与研究中心杨浩助理教授,题目是“数字人文时代古籍整理的机遇与挑战”。以下特摘编杨浩老师的部分讲稿,以分享给诸位对古籍数字化感兴趣的朋友。
古籍的数字化包括古籍的数字化保存,古籍转为可以检索的文本等,已经大大地改变了人们使用与利用古籍的习惯。为了对古籍进行更好的利用,对古籍进行数字化的整理必将是未来的一个重要课题。目前海内外学者已经在此方面做出了有益的探索,有的甚至已经用计算机实现了这样的初步设想。古籍的数字化整理前景非常广阔,非常值得我们去实现,为中华文明造福。
近些年来,已经有学者撰作了专门的著作,对此问题进行了探讨。比如:
吴洪泽,张家钧《计算机在古籍整理中的应用》,成都:四川大学出版社.2009.

《计算机在古籍整理中的应用》一书简述了古籍的数字化、各种汉字字库、古籍文本的编辑、古籍书版的制作、影印古籍的制作方法等。
王立清《中文古籍数字化研究》,北京:国家图书馆出版社.2011.

《中文古籍数字化研究》一书讨论了古籍数字化的基本理论问题、现状、主体分析、管理模式、影响等。
如果说上述书籍还没有涉及古籍的数字化整理问题,那么值得注意的是另外一套丛书,这套丛书叫“中国文化典籍计算机整理与开发技术研究系列”,有如下书籍:
常娥:《古籍计算机自动校勘自动编纂与自动注释研究》 芜湖:安徽师范大学出版社2013(下同)
衡中青:《古籍计算机全文数据库及内容挖掘研究 以〈方志物产·广东〉为例》
刘竟:《古籍计算机信息门户自动构建与应用 以农史学科为例》
黄建年:《古籍计算机自动断句标点与自动分词标引研究》
王雅戈:《古籍计算机自动索引研究 以民国农业文献自动索引为例》
曹玲,薛春香:《农业历史文献数字化建设研究》
我们看到,其中涉及到了古籍整理的绝大部分环节,比如校勘、编纂、标点,此外甚至还有自动注释、自动分词、自动索引等等。
在网上还能够搜索到很多学者撰写了有关的论文以及主持的课题。据本人所见,成熟的产品还没有见到,想必大家都在暗中努力。
古籍数字化整理的应用前景是很大的,上面那套丛书主要是农业方面的古籍,不要说古代文献涉及到严格意义上的古籍整理的,甚至近代文献,即便不需要严格的古籍整理,但也需要类似的整理。
方广锠老师实现了一个基于敦煌文献的整理平台,可以实现某种意义上的自动校勘,非常赞叹。

而且方老师长期做佛教藏外典籍的整理,有系统的构思,也发表了不少论文。
首都师范大学的尹小林老师也称实现了古籍的自动校勘、自动标点、自动排版等功能。但是没有向我们演示,不知道具体实现的如何。尹老师特别宣称他的自动标点已经达到百分之九十九的正确率。
总体上说,古籍数字化整理主要涉及自动校勘、自动标点两大部分,自动排版、自动注释等没有太多技术难度,不予讨论。
一些数字古籍网站
因为有些老师希望了解海内外数字化古籍较为集中的网站,所以今略为介绍如下:
国家图书馆
http://www.nlc.cn/dsb_zyyfw/gj/gjzyk/
国家图书馆有各种数字资源,据说至2017年年底还原其胶片为数字的资源要占到80%,这将极大地丰富我们的电子古籍总量,是古籍界的极大福音。另外,民国的期刊也有数字化的库。
CADAL中美百万册图书数字图书馆
http://www.cadal.zju.edu.cn/
中美百万是一个集各种古籍以及现代文献的大库,据说现代的数量已经超过300万册了,非常丰富。网上流行的各种djvu格式的电子书,据说都是从这个库流出来的。
书格
https://shuge.org/
发展的方向。国图与中美百万的绝大多数是黑白,这个在外来是要淘汰的,但是对于有比没有强的时代,还是非常有价值的。
Chinese Text Project
http://ctext.org/
书格网站的电子书虽然不很多,但是品质很高,高清彩图非常地赞,这样的古籍数字化是未来中国文本电子计划的网站,据说是一个学者制作的,非常厉害。里面可以检索到很多的古籍,也聚集了网站的各种加标点的文本。其中的古籍总量好像在2万以上,太惊叹了。我看到有不少古籍是来自互联网档案馆(www.archive.org),这个网站很神奇,有很多没有版权的各种语种的书籍,西文的很多,梵文的也很多,书都作了OCR,有pdf与djvu版的,而且很多书都把切边之前的彩图放在服务器上任人下载,太强大了。但是国内近几年好像上不了,挺可惜。
搜韵
http://sou-yun.com/eBookIndex.aspx
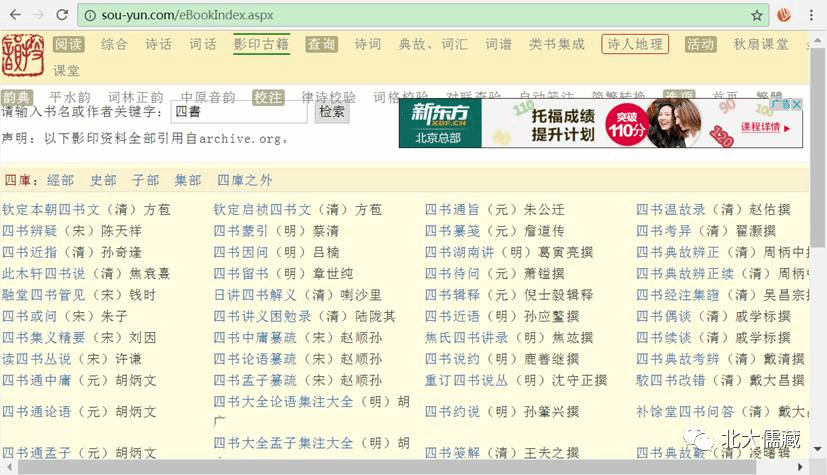
这个网站的书有不少就来自archive.org那个网站。
台湾“国家图书馆”古籍影像检索
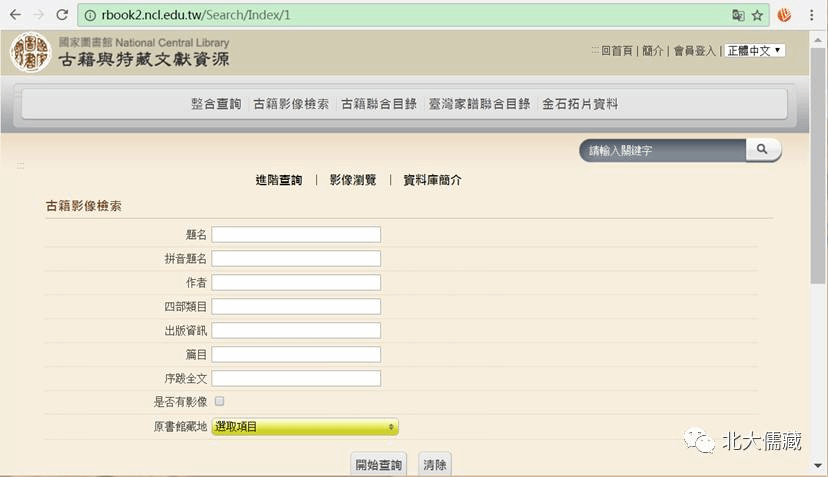
这个检索系统不错,也有不少有全文的古籍,是彩色的,可惜分辨率不高。
台湾“国立故宫博物院”善本古籍资料库
http://npmhost.npm.gov.tw/tts/npmmeta/RB/RB.html
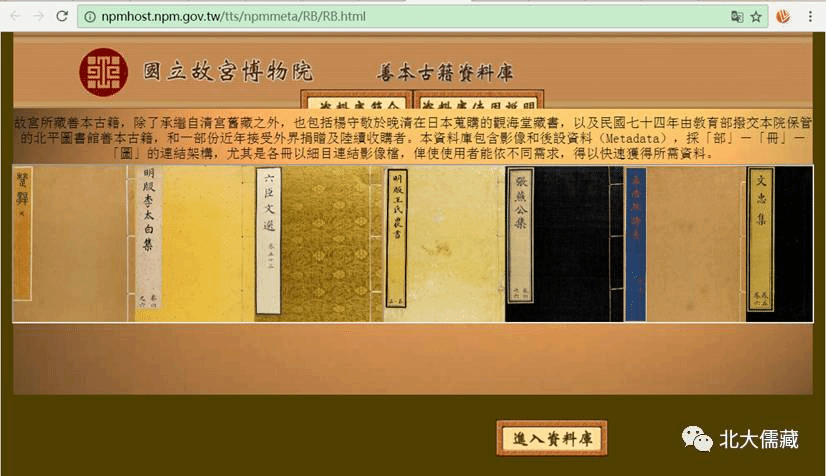
该网站也有不少古籍资源。
哈佛燕京图书馆中文善本特藏
http://hollis.harvard.edu/primo_library/libweb/action/search.do?vid=HVD

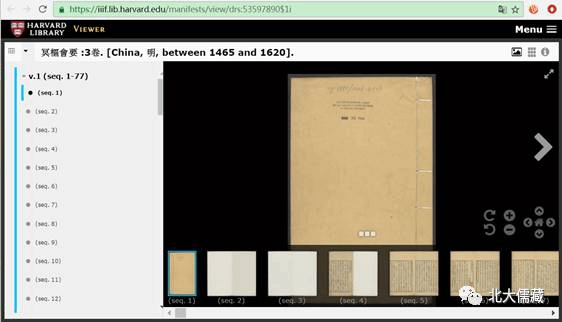
哈佛的库非常精彩,有很多好东西,可以直接下载。但据说从去年年底起,不能直接获取pdf了,发送到邮箱的链接也打不开了。但是,使用某(fan)种(qiang)技术还是可以下载的。
http://guides.library.harvard.edu/c.php?g=310134
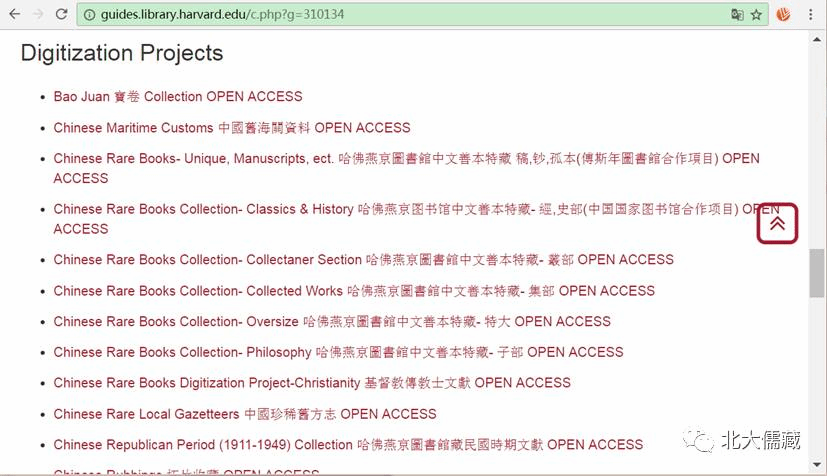
这个是他们电子化的计划列表,太强大了。
早稲田大学図书馆古典籍総合データベース
http://www.wul.waseda.ac.jp/kotenseki/index.html
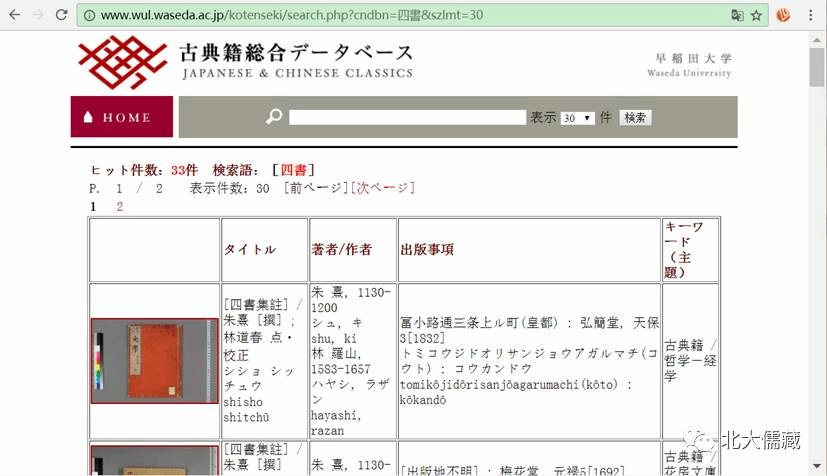
日本的古籍电子化实在太专业了,不仅可以任意下载,而且首页有标尺与色板,这样的彩色高清与专业电子化之后,真的是一劳永逸了,而且也能够达到保护古籍的效果。
东京大学东洋文化研究所所藏汉籍善本
http://shanben.ioc.u-tokyo.ac.jp/
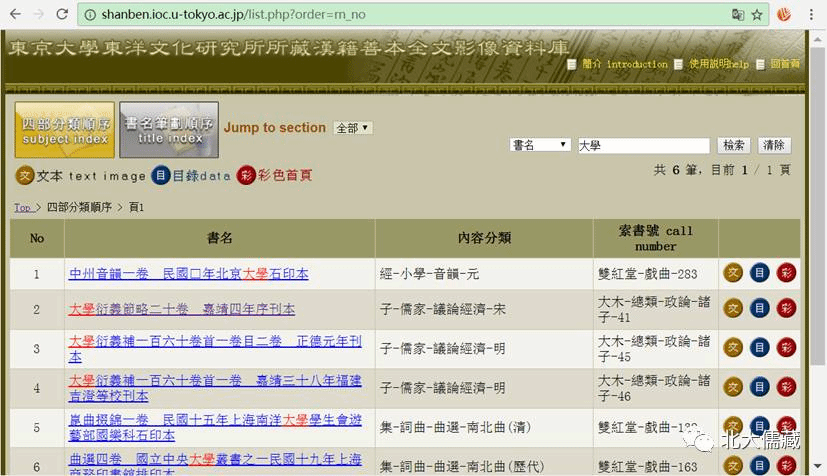
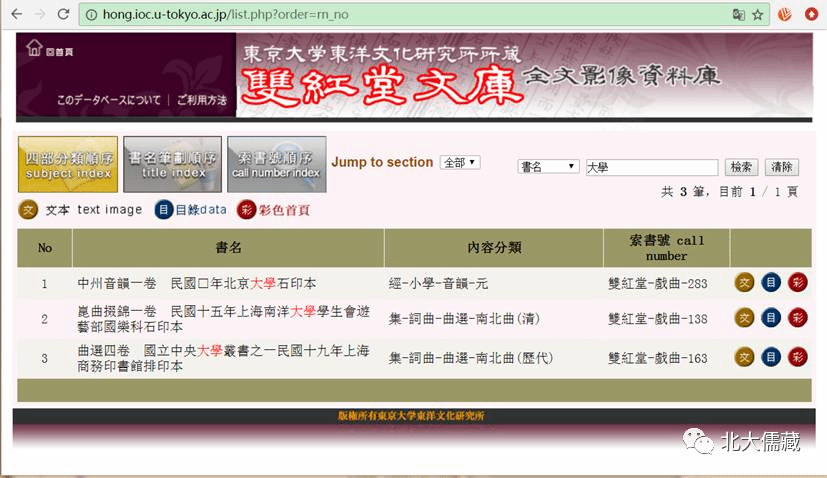
东京大学东洋文化研究所所藏双红堂文库
http://hong.ioc.u-tokyo.ac.jp/
国立国会図书馆デジタルコレクション
http://dl.ndl.go.jp/
以上几个库,都有很多书。特别是国会图书馆那个,有很多日本近代没有版权的图书。
有了强大的、丰富的数字化古籍资源,古籍数字化整理才有了一定的基础。
自动校勘
自动校勘,个别学者提出直接对图片进行比较,我认为不太可行。我认为,应该在OCR并校对的结果基础上进行比较。
自动校勘首先面临汉字标码的问题,我认为一定要将现有的OCR的系统改造为支持Unicode编码的系统,Unicode当中没有的可以使用组字式,採用类似CBETA的方案。
自动校勘要能够对异体字进行识别,定制,可以选择忽略。
既然叫自动校勘,必须使用计算机进行自动校勘,不能使用人工对齐各个文本。自动校勘使用的字符串算法是字符串相似度算法,实现起来非常容易,程序代码就十几行。
自动标点
使用云技术、中文断词技术等。这一块可能需要重点攻关。
专门号的标记
中国历代人物传记资料库(CBDB)项目
http://www.zggds.pku.edu.cn/006/cbdb/CBDB.htm

此项目积累了很多人名、朝代名、地名等数据,并且已经有Markus系统採用了此系统的数据,用于古籍的专门标记。
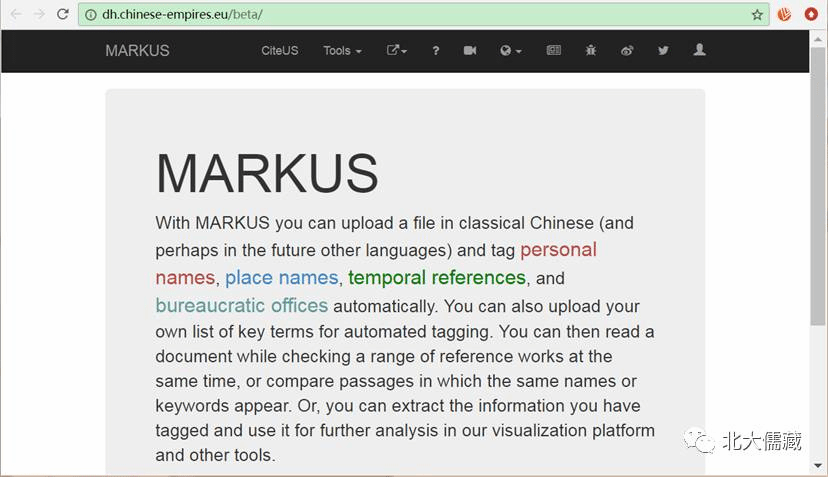
MARKUS 玛库斯平台
http://dh.chinese-empires.eu/beta/
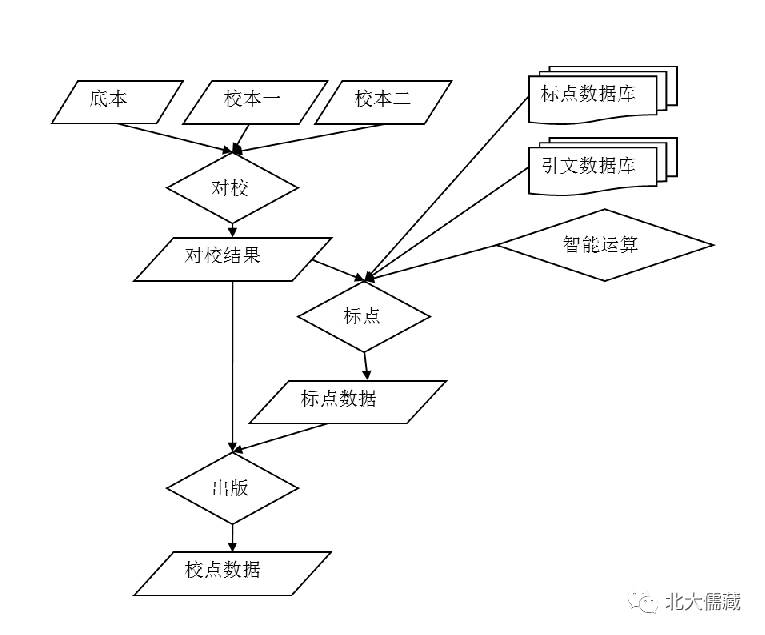
整体的流程可以如下图所示:
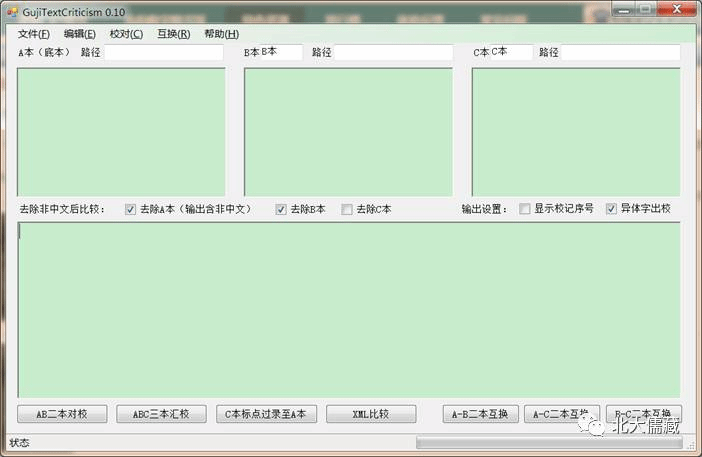
我自己实现了一个古籍自动对勘的小程序(以后会作为学衡小工具推出),目前能够实现一些小的功能。主要特点:支持Unicode文本、多本对校、忽略标点、异体字处理、标点过录、XML比较。
总的来说,古籍的数字化整理是未来必然的趋势,总体上要设计好底层,实现好自动校勘,开发好自动标点是关键。随著计算机与网络技术的发展,古籍数字化整理的梦想将实现,中华古老文明将在现代的计算机时代再次以新的方式绽放光彩。甚至更高级的自动注释、自动翻译、自动语音解读也不再是什麽神奇。


